Caffe2 adds 16 bit floating point training support on the NVIDIA Volta platform
After open sourcing Caffe2 at F8 last month, today we are are excited to share our recent work on low precision 16 bit floating point (FP16) training in collaboration with NVIDIA.
Deep learning workloads often have diverse compute requirements. We have long known that high precision computation like FP64 is not always necessary, and often use FP32 for training. However, many deep neural networks can be trained to a high degree of accuracy using even lower precision such as FP16.
We are working closely with NVIDIA to optimize Caffe2 for the features in NVIDIA’s upcoming Tesla V100, based on their next generation Volta architecture. Caffe2 is excited to be one of the first frameworks that is designed from the ground up to take full advantage of Volta by integrating the latest NVIDIA Deep Learning SDK libraries - NCCL and cuDNN.
Caffe2 with FP16 support will allow machine learning developers using NVIDIA Tesla V100 GPUs to maximize the performance of their deep learning workloads.
NVIDIA using the Tesla V100 and Caffe2 has initially seen 2.5x faster training with FP16 compared to Tesla P100, and up to 5x faster than Tesla K80 GPUs.
FP 16 training performance with NVIDIA Tesla GPUs (ResNet-50, Batch size: 64)
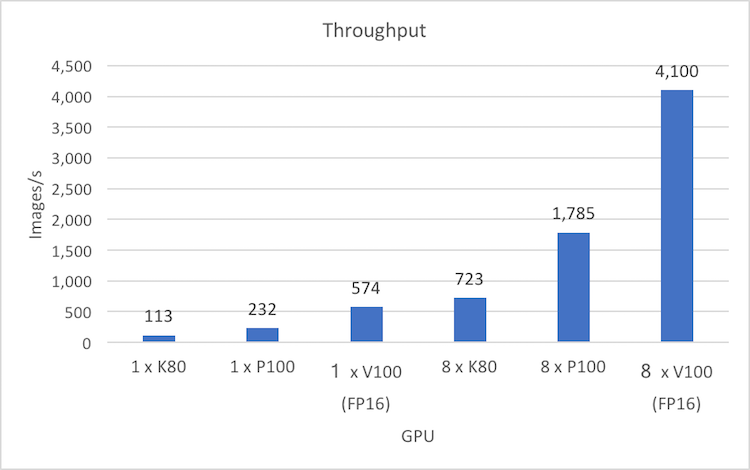
Configuration: Tesla K80 + cuDNN 6 (FP32), Tesla P100 + cuDNN 6 (FP32), Tesla V100 + cuDNN 7 (FP16)
Benchmark performance numbers are provided by NVIDIA using DGX-1 with Tesla P100 (Pascal) and DGX-1V with Tesla V100 (Volta) GPUs.
Caffe2 is open source and available at GitHub for download. Please check out the Caffe2 documentation & tutorials at Caffe2.ai. If you’re thinking about using Caffe2, we’re interested in hearing about your needs. Please participate in our survey. We will send you information about new releases and special developer events/webinars.
We will have our first Caffe2 meetup in San Francisco bay area at the end of May. Please join our Caffe2 meetup group.
- Homepage: https://caffe2.ai/
- Github: https://github.com/pytorch/pytorch
- Survey: https://www.surveymonkey.com/r/caffe2
- Meetup: https://www.meetup.com/Caffe2-Bay-Area