Caffe2 adds RNN support.
We are excited to share our recent work on supporting a recurrent neural network (RNN).
We did not support RNN models at our open source launch in April. So, over the last several months, we have developed state-of-the-art RNN building blocks to support RNN use cases (machine translation and speech recognition, for example).
Using Caffe2, we significantly improved the efficiency and quality of machine translation systems at Facebook. We got an efficiency boost of 2.5x, which allows us to deploy neural machine translation models into production. As a result, all machine translation models at Facebook have been transitioned from phrase-based systems to neural models for all languages. In addition, several product teams at Facebook, including speech recognition and ads ranking, have started using Caffe2 to train RNN models.
We invite machine learning engineers and researchers to experience Caffe2’s RNN capability. More details about what we implemented and open-sourced for RNN support are outlined below.
Unique Features in Caffe2 RNNs
Caffe2 provides a generic RNN library where the RNN engine is an almost zero-overhead virtual box for executing arbitrary RNN cells. Under the hood, a cell is just a smaller Caffe2 network and benefits from all typical Caffe2 performance advantages. We also have a rich set of APIs that let people use existing RNNCells and implement new ones using Python. MultiRNNCell allows for easy composition of existing cells into more complex ones. For example, you could combine several layers of LSTMCells and then put an AttentionCell on top.
The underlying RNN engine is incredibly flexible. It allows you to select which outputs have gradients and need to be propagated through time, and to define how cells are connected to each other and how they connect to outside world. Each input receives the correct gradient propagated back through time.
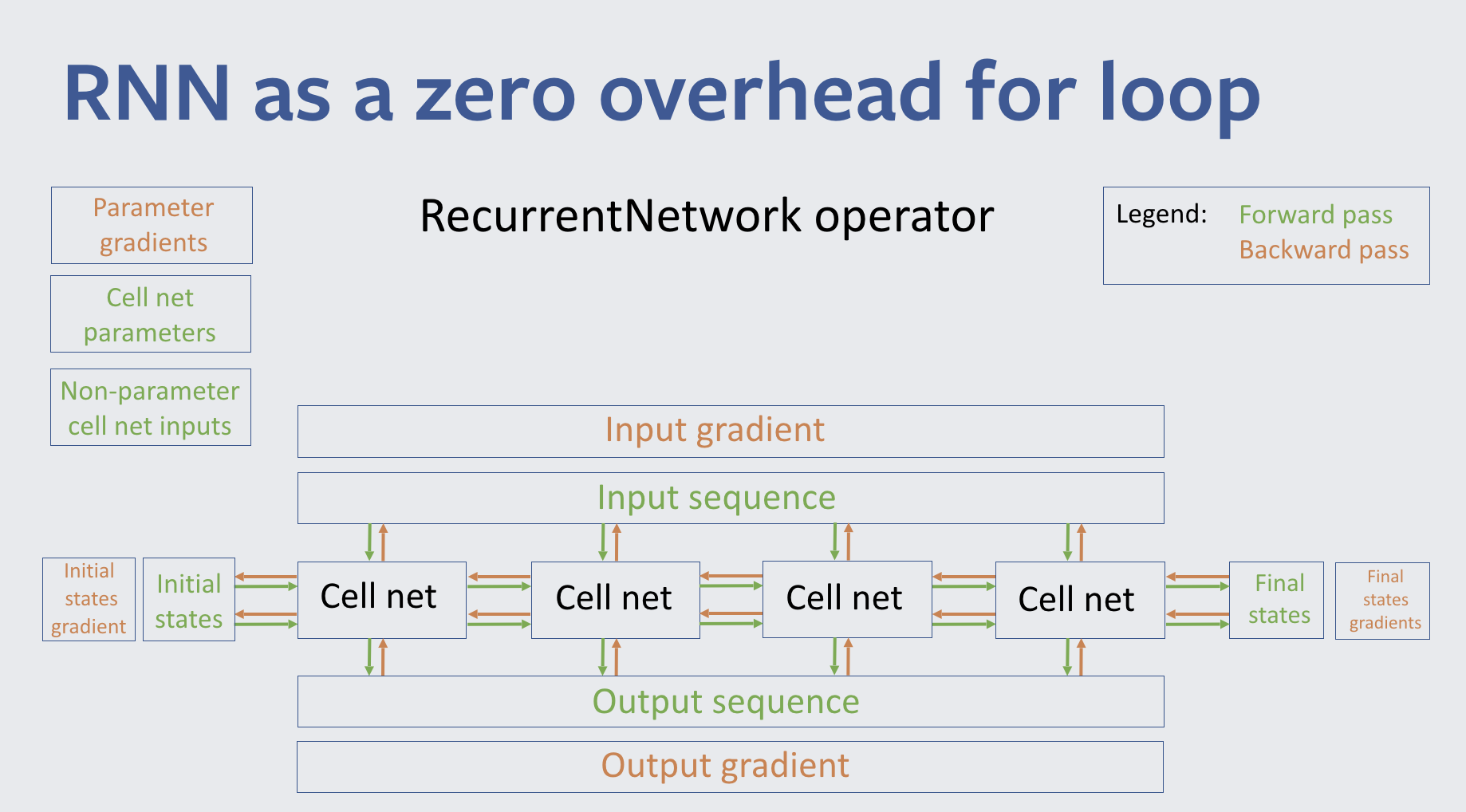
The zero-overhead engine is not the only performance win. Another key advantage comes in memory, which allows us to use a large batch size per GPU. The RNN engine supports the recycling of intermediate results across time steps and gives you the power to decide what to recycle. See here for a more detailed analysis of trading memory for compute.
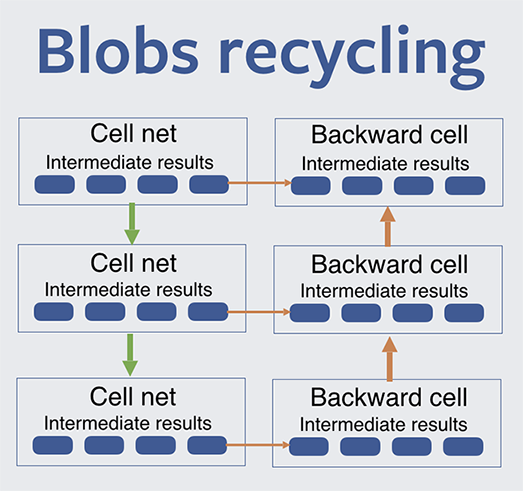
In the diagram above, intermediate results of the backward pass could be reused across time steps. The forward ones, if reused, cause a need to be recomputed on the backward pass. Caffe2 allows you to specify which forward blobs should be dropped to trade compute for memory.
Static RNN
Caffe2 also implements a so-called static RNN. It can be used when back-propagating through time when the sequence length is known in advance. Then, the recurrent net becomes a part of the containing graph, so the global neural network executor, DAGNet, will find the most optimal parallel execution way of running the RNN within the context of the whole model. The static RNN engine supports all existing RNNCells and can be plugged in with almost no changes to the code. For multi-layered LSTM models, we saw a 25 percent speedup over the dynamic RNN implementation.
RNN engine for Beam Search
We follow the practice, common in machine translation, of using beam search at decoding time to improve our estimate of the highest-likelihood output sentence according to the model. We exploited the generality of the RNN abstraction in Caffe2 to implement beam search directly as a single forward network computation, which gives us fast and efficient inference. Beam search decoding as a recurrent network is used regardless of the architecture of the underlying model (RNN, CNN, etc.). We have also open-sourced this method of beam search inference as part of the Caffe2 library.
- Homepage: https://caffe2.ai/
- Github: https://github.com/pytorch/pytorch
- Facebook: https://facebook.com/Caffe2AI