Learn More
Caffe2 is a machine learning framework enabling simple and flexible deep learning. Building on the original Caffe, Caffe2 is designed with expression, speed, and modularity in mind, and allows a more flexible way to organize computation.
What Is Deep Learning?
Deep learning is one of the latest advances in Artificial Intelligence (AI) and computer science in general. In a nutshell, deep learning extracts and transforms features through the processing of subsequent layers of data, where each successive layer uses the output from the previous layer as input. In many ways, it is the next generation of machine learning and often works hand-in-hand with existing machine learning processing.
To better understand what Caffe2 is and how you can use it, below are a few examples of machine learning and deep learning in practice today.
Check out other applications of deep learning as well.
Examples of Deep Learning
Want to see some examples of how deep learning works without doing all of the setup? Try out some demos:
Style Transfer
Style transfer is a technique to change a photo or video to reflect a particular style. You may have seen examples of this in Photoshop over the years or recently filters that turn photos into van Gogh’s Starry Night or Munch’s Scream. Deep learning has allowed this process to be optimized to the point where you don’t need expensive photo editing tools or a powerful desktop computer. It can run on the phone and it can even be applied to video in real-time. Check out video below for an example of the style transfer features Caffe2 enabled for Facebook’s Messenger app.
Caffe Neural Network for Image Classification
Caffe is well known for its capability for image-based neural networks which can be useful in automatically identifying objects in images and video. This example lets you upload images and it will return the top five results for what was detected in the image.

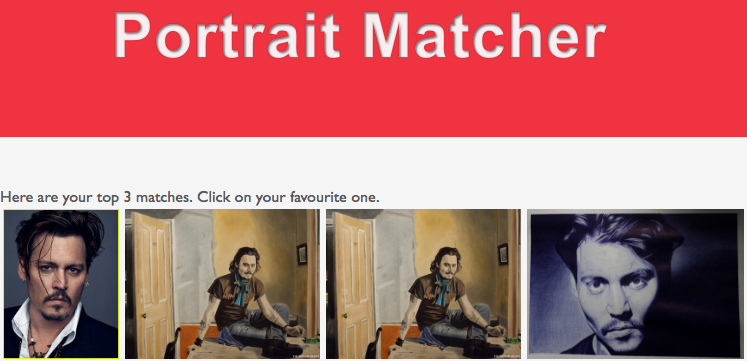
Portrait Matcher
This portrait matching application is a fun example of the power of neural networks and how they’re getting closer to mimicking human’s capabilities with identifying look-a-like faces. It uses a database of celebrity images as its training set and uses [artwork][http://deviantart.com] made by a wide variety of artists and in many different styles as its test dataset.
Caffe2 Philosophy
The philosophy of Caffe2 is the same as Caffe, and the principles that direct its development can be summed up in six points:
- Expression: models and optimizations are defined as plaintext schemas instead of code.
- Speed: for research and industry alike speed is crucial for state-of-the-art models and massive data.
- Modularity: new tasks and settings require flexibility and extension.
- Openness: scientific and applied progress call for common code, reference models, and reproducibility.
- Community: academic research, startup prototypes, and industrial applications all share strength by joint discussion and development in a BSD-2 project.
Why Use Caffe2?
Deep Learning has the potential to bring breakthroughs in machine learning and artificial intelligence. Caffe2 aims to provide an easy and straightforward way for developers to experiment with deep learning first hand.
In some cases you may want to use existing models and skip the whole “learning” step and get familiar with the utility and effectiveness of deep learning before trying train your own model.
Working with Caffe2
First, make sure you have installed Caffe2.
When you are first getting started with deep learning and Caffe2, it will help to understand the workflow of how you will create and deploy your deep learning application. There are two primary stages for working with a deep learning application built with Caffe2:
- Create your model, which will learn from your inputs and information (classifiers) about the inputs and expected outputs.
- Run the finished model elsewhere. e.g., on a smart phone, or as sub-component of a platform or a larger app.
Creating the model usually takes some significant processing power and time. While you can get away with just using your laptop’s CPU to create and train your deep learning neural network with Caffe2, you may find that for more complicated models with a lot of inputs that this takes too long. Fortunately, you can use the power of GPUs to massively speed up this process. One method of development is to work with a subset of data on your standard PC or small cloud instance, but then run the training of the model with all of the data on a cloud instance with large GPU capacity.
Running the model ends up being relatively lightweight in the sense that even if you took millions of images as inputs, the output that is used when running is much smaller. For example, using 50000 images as inputs might have been several GBs of data, but the output model might only be 200 MB.
Next up, Caffe2 Tutorials in IPython notebooks, or if you want to read a walkthrough of the basic Caffe2 components, jump ahead to read the Intro Tutorial.